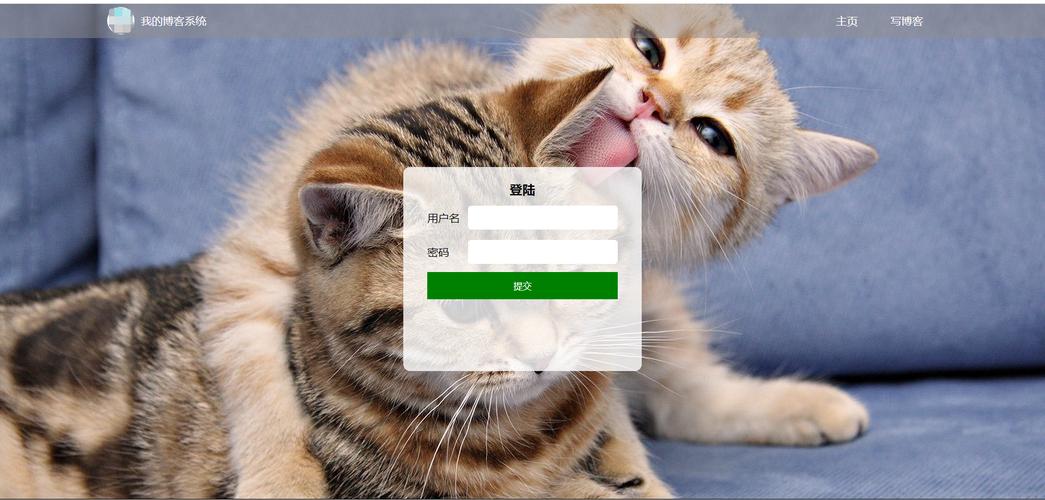
这时候就得学数据库了。
C++中二叉树遍历有四种主要方式:1. 前序遍历(根-左-右),递归或栈实现;2. 中序遍历(左-根-右),常用于BST获取有序序列;3. 后序遍历(左-右-根),适用于释放内存;4. 层序遍历(广度优先),使用队列按层访问节点。
1. 定义产品基类和具体产品类 首先定义一个抽象的产品基类,提供统一的接口。
性能考量: 对于大多数常见的数据规模,上述两种方法的性能差异不大。
使用PHP命令行(CLI)可以高效地完成这类任务,适合定时任务、后台脚本或与Shell脚本集成。
这种方式实现简单,但性能差、存在单点瓶颈,一般只在没有中间件依赖的场景下临时使用。
值得注意的是,存储过程本身的名称可以长达64个字符。
1. 使用临时变量交换 这是最基础、最直观的方法,适用于所有数据类型。
传统的做法是使用 if 语句进行判断,但这种方式在处理多个元素时会显得冗长且不易维护。
3. 多对多关系配置(EF Core 5+ 支持自动生成中间表) 例如,“学生”和“课程”是多对多关系。
super() 关键字的核心作用 在面向对象编程中,继承是实现代码复用和扩展性的重要机制。
本文旨在帮助读者理解并解决在使用PySpark进行数据Join操作时遇到的“列名歧义性(Column Ambiguity)”错误。
将原始代码中的 for i in range(len(input_string))] 和 input_string[i] 替换为 for c in input_string] 和 c,可以得到第一个优化版本:input_string = input() # 移除冗余的str() print(' '.join(sorted([c if (ord(c) - 97) % 2 == 0 else c.upper() for c in input_string] , reverse=True)))在这个版本中,我们已经移除了 str() 的冗余调用,并采用了更Pythonic的字符迭代方式。
关键在于合理设计线程模型、任务队列与调度策略。
理解其原理有助于构建更安全可靠的Web应用。
CSV文件里的数据格式往往不那么规范,你可能需要检查字段数量、数据类型,甚至对某些字段进行清洗,比如去除多余的空格,或者转换日期格式。
通过掌握groupby().transform()、shift()和expanding()这三个Pandas功能,您可以高效且简洁地解决分组数据中涉及前置元素累积统计的复杂问题,极大地提升数据处理的效率和代码的可读性。
限制上传目录: 确保所有上传的文件都存储在一个专门的、权限受限的目录中,并且这个目录不能被Web服务器直接执行脚本。
使用 go mod graph 查看依赖关系 进入你的 Go 模块项目根目录,执行: go mod graph 输出示例如下: example.com/myapp github.com/gin-gonic/gin@v1.9.0 github.com/gin-gonic/gin@v1.9.0 gopkg.in/yaml.v2@v2.4.0 github.com/gin-gonic/gin@v1.9.0 github.com/golang/protobuf@v1.5.0 这表示 myapp 依赖 gin,gin 又依赖 yaml 和 protobuf。
这是因为实体的祖先路径是实体键的一部分,改变祖先路径实际上相当于创建了一个新的实体。
本文链接:http://www.roselinjean.com/429522_4252c3.html